-
딥러닝 이론-7-1 : Learning rate, data preprocessing, overfitting딥러닝 2023. 7. 6. 21:59
1. Learning rate
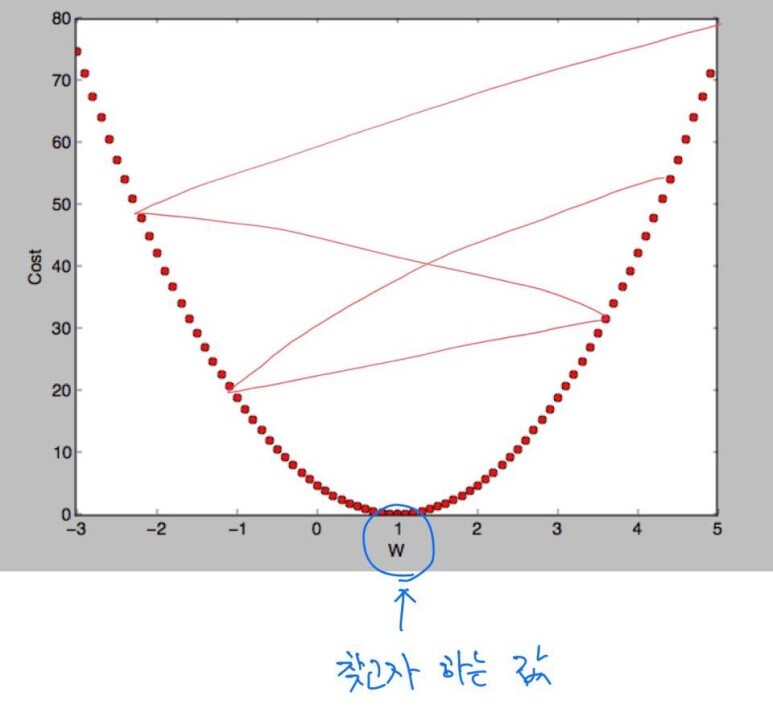
- 앞서 gradient descent algorithms을 통해 cost를 줄여나간다고 하였다. 그럼 학습이 진행되면서 얼마만큼 cost를 줄여나가기 위해 움직일까? 그것을 결정해주는 것이 learning rate이며, 이것은 우리가 지정해줄 수 있다.(hyperparameter) learning rate이 너무 크게 되면 우리가 찾고자하는 w값을 찾지 못하고 밖으로 튕겨나가는 overshooting이 될 수 있다. (왼쪽 그래프) 반대로 learning rate이 너무 작게 되면 시간이 오래 소요되고 시간이 다 되어 우리가 찾고자하는 최저점이 아닌 곳에서 stop할 수 있다. (오른쪽 그래프) 따라서 적절한 learning rate을 설정해주는 것이 필요하다.

모두를 위한 딥러닝 강의에서는 0.01 을 처음 시작하는 learning rate 값으로 추천한다. 하지만 결국 가장 적합한 rate의 값은 학습을 진행하면서 확인해야 한다!
2. Data preprocessing
- 보통 데이터로 주어진 값들 간의 차이가 크게 되면 learning rate이 적정 값임에도 overshooting 이 일어날 수 있다. 따라서 이를 위해 데이터 전처리과정이 중요하다. 데이터 전처리 방법으로는 데이터 중심이 0이 되도록 하는 zero-centered data, 데이터 값이 일정 범위 안에 있도록 하는 normalized data 방법이 있다.

3. Overfitting
- 설계한 모델이 training dataset에 너무 정확도가 높을 경우, test dataset이나 실제 사용에서 좋은 성능을 발휘하지 못할 수 있다. 이것이 바로 overfitting이다. 쉽게 말해 우리가 2019년 수능만 10번 풀어 보았다고 하자. 그러면 11번째 풀었을 때 100점을 맞는데, 우리는 우리가 처음 본 문제처럼 풀이를 해 답을 맞출 수도 있지만 답을 외워서 맞추는 경우도 있을 것이다. 이런 경우 우리가 2020년 수능을 보면 똑같이 100점을 맞을 수 있을까??? 없다!!바로 overfitting이 이런 것이다.
overfitting을 줄이는 방법은 여러가지가 있는데 먼저 가장 좋은 방법은 더 많은 training data로 학습하는 것이다. 그 다음으로는 feature의 수를 줄이거나 regularization(일반화) 방법이 있다. regularization은 weight 값을 너무 큰 값을 취하지 않는 것이다. (weight 의 제곱 값을 합하여 값을 최소화)
'딥러닝' 카테고리의 다른 글
딥러닝 이론-8-1 : 딥러닝 기본 개념 1 (0) 2023.07.09 딥러닝 이론-7-2 : Learning and test data sets (0) 2023.07.07 딥러닝 이론-6 : Softmax Classification (0) 2023.07.05 딥러닝 이론-5 : Logistic regression classification (0) 2023.07.04 딥러닝 이론-4 : Multivariable linear regression (0) 2023.07.03